Level of Difficulty: Intermediate – Senior.
Have you ever run into a situation where you have over 200 students whose work needs to be marked and the admin around it is enough to make anyone go crazy? Well here’s a step towards getting around the labour-intensive admin that goes hand-in-hand with marking student projects, using Google Drive, Google Sheets and a Google Colaboratory Python script.
What are the steps?
The steps that we will be following are:
- Setup the project in the Google Developer Console
- Create a service account
- Download the service account key file
- Create the Google Drive folder and content
- Create a new Google sheet for the rubric template
- Create a new Google sheet for the class list
- Create a new Google sheet for the class results
- Create the Python script
- Create ‘Replicate Rubric for Students’ script
- Create ‘Update Class Results’ script
Deep Dive
Let’s dive deeper into the steps listed above.
Setup Project in Google Developer Console
Create Service Account
Create a New Project in the Google Developer Console:

Make sure your newly created project has been selected before you start enabling APIs and creating service accounts:

Under APIs & Services, navigate to Credentials:

Add a new Service account:

Give your service account a name:

Retrieve the Service Account Key
Edit the service account you’ve just created in order to create a key:

Select Keys, then select Create New Key from the Add Key dropdown:

Select JSON then click Create and Save the Key.json file to your computer:

Enable APIs
Navigate to and enable the Google Drive API:

Navigate to and enable the Google Sheets API:

Create Google Drive Folder and Content
Please note that all the Google Drive Content is available in the GitHub Repo if you’d like to upload the files I’ve used for this post.
Navigate to Google Drive and Create a root folder that you will use to store all of your collateral:

Share the folder you’ve just created with the service account that you’ve also just created:

Create a new Google Sheet to store the template of your rubric to be replicated for each student:

The template rubric may look something like this:

In this case, the Indicator field will contain either a 1 (for yes, criteria is present in student submission) or a 0 (for no, criteria is not present in student submission), resulting in the mark either equating to the weight of the criteria, or 0. The formula of the mark field may need to be adapted to cater for your needs if you are using a sliding scale form of evaluation.
Next, create a new Google Sheet to store the list of student information to be used:
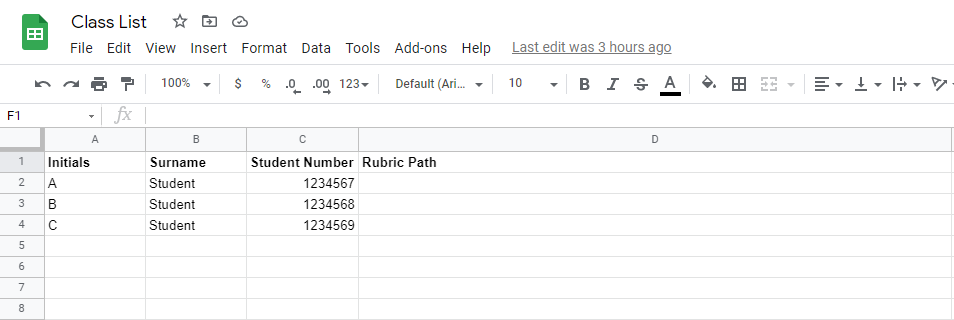
Create a new Google Sheet named Results to store the class results:

Create Python Script
Replicate Rubric for Every Student
You’ll first need to run the following commands to ensure that the following libraries are installed:
pip install oauth2client
pip install PyOpenSSL
pip install gspread
pip install pydrive
Then you’ll want to import the following libraries:
import pandas as pd
import gspread
import io
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from oauth2client.service_account import ServiceAccountCredentials
from google.colab import files #comment out if you aren't using Google Colab
Next, you’ll want to initialise your authorisation with Google, replacing ‘<YOUR KEY FILE PATH>‘ with the path to the service account key downloaded from the Google Developer Console:
# Init Google (with Auth)
file_path = r"<YOUR KEY FILE PATH>.json"
scope = ['https://spreadsheets.google.com/feeds',
'https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name(file_path, scope)
# Used to auth Google Sheets
gc = gspread.authorize(credentials)
# Used to get all files in Google Drive folder
gauth = GoogleAuth()
gauth.credentials = credentials
drive = GoogleDrive(gauth)
In order to create a rubric for each student, you’ll need to access the populated class list created in the Google Drive Folder:
# Open Spreadsheet
spreadsheet = gc.open('Class List')
# Get Student Class List
student_list_sheet = spreadsheet.get_worksheet(0)
student_list = student_list_sheet.get_all_values()
student_headers = student_list.pop(0)
# Read Student Class List into DataFrame
df_students = pd.DataFrame(student_list, columns=student_headers)
df_students
For every student in the class list (df_students), create the rubric. Replace ‘<YOUR FOLDER ID>‘ with the folder ID in which you’d like to store all of the student rubrics. It would be advisable to create a subfolder, named Student Rubrics in the Google Drive root folder:
template_spreadsheet = gc.open('Template_Rubric')
detailed_rubric = template_spreadsheet.get_worksheet(0)
rubric_summary = template_spreadsheet.get_worksheet(1)
for index, element in df_students.iterrows():
print(element['Student Number'])
# Create Workbook
workbook = gc.create('{}_Rubric'.format(element['Student Number']), folder_id='<YOUR FOLDER ID>')
# Update Rubric Path (in Student Class List)
sheet_id = workbook.id
sheet_url = 'https://docs.google.com/spreadsheets/d/{}/'.format(sheet_id)
# Update Student Rubric Path
student_list_sheet.update('D{}'.format(index + 2), sheet_url)
# Duplicate Spreadsheets
detailed_rubric_worksheet = detailed_rubric.copy_to(spreadsheet_id=workbook.id)
rubric_summary_worksheet = rubric_summary.copy_to(spreadsheet_id=workbook.id)
# Delete Sheet1
worksheet = workbook.sheet1
workbook.del_worksheet(worksheet)
# Get Duplicated Spreadsheets
student_spreadsheet = gc.open('{}_Rubric'.format(element['Student Number']))
detailed_rubric_worksheet = student_spreadsheet.get_worksheet(0)
rubric_summary_worksheet = student_spreadsheet.get_worksheet(1)
# Update Sheetnames
detailed_rubric_worksheet.update_title('Detailed Rubric')
rubric_summary_worksheet.update_title('Rubric Summary')
# Update Student Information
detailed_rubric_worksheet.update('B1', str(element['Initials']))
detailed_rubric_worksheet.update('B2', element['Surname'])
detailed_rubric_worksheet.update('B3', element['Student Number'])
# Update #REFs in Student Rubric - Student Information
for row in range(1, 5, 1):
# Get Formula
cell = rubric_summary_worksheet.acell(f'B{row}', value_render_option='FORMULA').value
# Set Formula
rubric_summary_worksheet.update(f"B{row}", cell, raw=False)
# Update #REFs in Student Rubric - Student Summary Marks
for row in range(7, 19, 1):
# Get Formula
cell = rubric_summary_worksheet.acell(f'D{row}', value_render_option='FORMULA').value
# Set Formula
rubric_summary_worksheet.update(f"D{row}", cell, raw=False)
The above code block will not only create a new rubric, but also fill in the information available in the class list and correct any corrupt formulas. If you change the contents of your rubric, please pay careful attention to the indexes used above to update formulas. If you are not using formulas extensively, feel free to remove the formula manipulation code.
Update Class Results
Create a method, named GetData, which will pull of the rubric data from the student rubrics. This method will be reused to process the data from every student’s rubric file stored on the drive:
def GetData(workbook):
# Open Spreadsheet
spreadsheet = gc.open(workbook)
# Retrieve Student Number From Spreadsheet
student_number = spreadsheet.get_worksheet(1).get('B3') # saves as list of list
student_number = student_number[0][0]
# Get Detailed Rubric
detailed_rubric = spreadsheet.get_worksheet(0).get('A6:H42')
rubric_headers = detailed_rubric.pop(0)
# Get Category Rubric
category_rubric = spreadsheet.get_worksheet(1).get('G6:J9')
category_rubric_headers = category_rubric.pop(0)
# Get Sub-Category Rubric
sub_category_rubric = spreadsheet.get_worksheet(1).get('A6:E17')
sub_category_rubric_headers = sub_category_rubric.pop(0)
# Get Total
total = spreadsheet.get_worksheet(1).get('I10') # saves as list of list
total = total[0][0]
# Read Rubrics into DataFrame
df_category_rubric = pd.DataFrame(category_rubric, columns=category_rubric_headers)
df_sub_category_rubric = pd.DataFrame(sub_category_rubric, columns=sub_category_rubric_headers)
df_detailed_rubric = pd.DataFrame(detailed_rubric, columns=rubric_headers)
# Return all of the dataframes, the student_number and the total
return df_category_rubric, df_sub_category_rubric, df_detailed_rubric, student_number, total
Create a method, named ProcessResults, which will process and write the results from the student rubric file into the main class results file. This method will be reused by the method created below to store the results on different levels of granularity, (Category, Sub-Category, Criteria and Results) in different sheets:
def ProcessResults(df_entry_raw, sheet_index, student_number, transpose=True, has_student_number=False):
try:
if transpose:
# Transpose dataframe
df_entry_transpose = df_entry_raw.transpose()
# Make the Result Row the Headers
df_entry = df_entry_transpose.rename(columns=df_entry_transpose.iloc[0])
# Remove the Result Row
df_entry = df_entry.iloc[1: , :]
# Remove 'Mark' as the Index
df_entry = df_entry.reset_index(drop=True)
else:
df_entry = df_entry_raw
# If the student number is not provided in the dataset, assign it
if has_student_number == False:
# Add Student Number Column
df_entry['Student Number'] = student_number
# Move Student Number Column to the Front of the DataFrame
cols = list(df_entry.columns)
cols = [cols[-1]] + cols[:-1]
df_entry = df_entry[cols]
# Write to Excel if something changes, get the new columns and add it to the Results sheet
#df_entry.to_excel('{} Results.xlsx'.format(sheet_index), index=False)
# Open Results Spreadsheet
spreadsheet = gc.open("Results")
# Records
results_worksheet = spreadsheet.get_worksheet(sheet_index)
results_records = results_worksheet.get_all_values()
results_headers = results_records.pop(0)
# Read Results Records into DataFrame
df_results = pd.DataFrame(results_records, columns=results_headers)
# Check if Student Results Already Recorded
if (df_results['Student Number'] == student_number).any():
# Get Index of Current Student Number
indexes = df_results.index[df_results['Student Number'] == student_number].tolist()
for index in indexes:
# Drop old Record
df_results = df_results.drop(index)
# Add Student Record
df_results = df_results.append(df_entry)
results_worksheet.update(
[df_results.columns.values.tolist()] + [[vv if pd.notnull(vv) else '' for vv in ll] for ll in df_results.values.tolist()]
)
return True
except Exception as e:
print(e)
return False
Create a method, named ProcessStudentResults, which will break up the results in different levels of granularity and parse it through ProcessResults to be written into the class results workbook:
def ProcessStudentResults(workbook):
status = False
results = GetData(workbook)
df_category_rubric = results[0]
df_sub_category_rubric = results[1]
df_detailed_rubric = results[2]
student_number = results[3]
total = results[4]
# Filter columns: Detailed Results
df_entry_raw = df_detailed_rubric[['Criteria','Mark']]
# criteria table: first tab (0) in workbook
status = ProcessResults(df_entry_raw, 0, student_number=student_number)
# Detailed Results Processed Successfully -> Filter columns: Sub-Category Results
if status:
print('Detailed Results Updated')
df_entry_raw = df_sub_category_rubric[['Sub-Category','Mark']]
# second tab (1) in workbook
status = ProcessResults(df_entry_raw, 1, student_number=student_number)
else:
print('Detailed Results NOT Updated')
# Sub-Category Results Processed Successfully -> Filter columns: Category Results
if status:
print('Sub-Category Results Updated')
df_entry_raw = df_category_rubric[['Category','Mark']]
# third tab (2) in workbook
status = ProcessResults(df_entry_raw, 2, student_number=student_number)
else:
print('Sub-Category Results NOT Updated')
# Category Results Processed Successfully -> Add Total and Display
if status:
print('Category Results Updated')
df_entry_raw = pd.DataFrame(data=
{
'Student Number': [student_number],
'Total': [total]
},
columns=['Student Number','Total'])
# Results tab (tab 3) in the file
status = ProcessResults(df_entry_raw, 3, transpose=False, has_student_number=True, student_number=student_number)
if status:
print('Total Updated')
else:
print('Total NOT Updated')
else:
print('Category Results NOT Updated')def ProcessStudentResults(workbook):
status = False
results = GetData(workbook)
df_category_rubric = results[0]
df_sub_category_rubric = results[1]
df_detailed_rubric = results[2]
student_number = results[3]
total = results[4]
# Filter columns: Detailed Results
df_entry_raw = df_detailed_rubric[['Criteria','Mark']]
# criteria table: first tab (0) in workbook
status = ProcessResults(df_entry_raw, 0, student_number=student_number)
# Detailed Results Processed Successfully -> Filter columns: Sub-Category Results
if status:
print('Detailed Results Updated')
df_entry_raw = df_sub_category_rubric[['Sub-Category','Mark']]
# second tab (1) in workbook
status = ProcessResults(df_entry_raw, 1, student_number=student_number)
else:
print('Detailed Results NOT Updated')
# Sub-Category Results Processed Successfully -> Filter columns: Category Results
if status:
print('Sub-Category Results Updated')
df_entry_raw = df_category_rubric[['Category','Mark']]
# third tab (2) in workbook
status = ProcessResults(df_entry_raw, 2, student_number=student_number)
else:
print('Sub-Category Results NOT Updated')
# Category Results Processed Successfully -> Add Total and Display
if status:
print('Category Results Updated')
df_entry_raw = pd.DataFrame(data=
{
'Student Number': [student_number],
'Total': [total]
},
columns=['Student Number','Total'])
# Results tab (tab 3) in the file
status = ProcessResults(df_entry_raw, 3, transpose=False, has_student_number=True, student_number=student_number)
if status:
print('Total Updated')
else:
print('Total NOT Updated')
else:
print('Category Results NOT Updated')
For each student file, you’re going to want to execute ProcessStudentResults. Replace ‘<YOUR FOLDER ID> with the folder ID that contains all student rubrics:
# View all folders and file in your Google Drive
file_list = drive.ListFile({'q': "'<YOUR FOLDER ID>' in parents and trashed=false"}).GetList()
for file in file_list:
if 'rubric' in file['title'].lower() and 'template' not in file['title'].lower():
print(file['title'])
ProcessStudentResults(file['title'])
print('\n')
Did this work for you? Did you find any enhancements to the code that could be implemented? Feel free to fork the code on GitHub and make pull requests with any enhancements.
Want to visualise the data gathered from the rubrics? Here’s a blog post on how you can connect a Google Sheet to Power BI.
If you have any feedback, or if you got stuck somewhere, feel free to reach out via email (jacqui.jm77@gmail.com) or drop a comment below.
